
深層学習:人工知能を支える技術の核心

DXを学びたい
深層学習って、結局何がすごいんですか? 人間の脳みそみたいって言われても、いまいちピンとこなくて。

DXアドバイザー
良い質問ですね。深層学習のすごいところは、大量のデータから複雑なパターンを自動的に見つけ出せる点です。例えば、たくさんの猫の画像を見せることで、猫の特徴を自分で学習し、初めて見る猫の画像でも猫だと認識できるようになるんです。
DXを学びたい
なるほど! じゃあ、猫の画像がたくさんあればあるほど、より正確に猫を識別できるようになるんですね。
DXアドバイザー
その通りです。データ量が多いほど、コンピューターはより多くの特徴を捉え、より正確な判断ができるようになります。これが、深層学習が画像認識や音声認識などの分野で非常に高い精度を誇る理由の一つです。
深層学習とは。
デジタル技術を活用した変革に関連する用語である「深層学習」は、人間の脳の仕組みを模倣した情報処理の方法です。これは、音声の理解や写真の中身の特定、区別、予測など、人が行っている作業をコンピューターに学習させる技術の一つです。大量のデータを用いて、コンピューター内の回路を調整し、より正確な分析や判断ができるようにしていきます。
深層学習の基礎

深層学習は、現代の人工知能の中核となる技術です。音声や画像認識、自然な言葉の理解など、これまで人が得意としていた難しい作業を、計算機で実現します。その基本は、人の脳の神経回路を模した「多層神経回路網」という数理的な構造です。これは、多数の層が重なり、各層は互いに繋がった多数の単位で構成されています。入力された情報に対し、各単位が計算を行い、結果を次の層へ伝えます。この繰り返しで、複雑な規則性や関連性を学習します。従来の機械学習と異なり、深層学習は、データの特徴を自動で学習できる点が強みです。従来は人が手作業で特徴を設計する必要がありましたが、深層学習では大量のデータを与えるだけで、最適な特徴を抽出します。しかし、課題もあります。学習には膨大な量のデータが必要であり、学習結果の解釈が難しい場合があります。データが少ない場合や、判断の根拠を説明する必要がある場合には、他の手法が適していることもあります。
| 特徴 | 説明 |
|---|---|
| 基本構造 | 多層神経回路網(多数の層が重なり、各層は互いに繋がった多数の単位で構成) |
| 動作原理 | 各単位が入力情報に対し計算を行い、結果を次の層へ伝達 |
| 強み | データの特徴を自動で学習可能 (特徴設計が不要) |
| 課題 | 膨大な量のデータが必要、学習結果の解釈が難しい |
ニューラルネットワークの仕組み

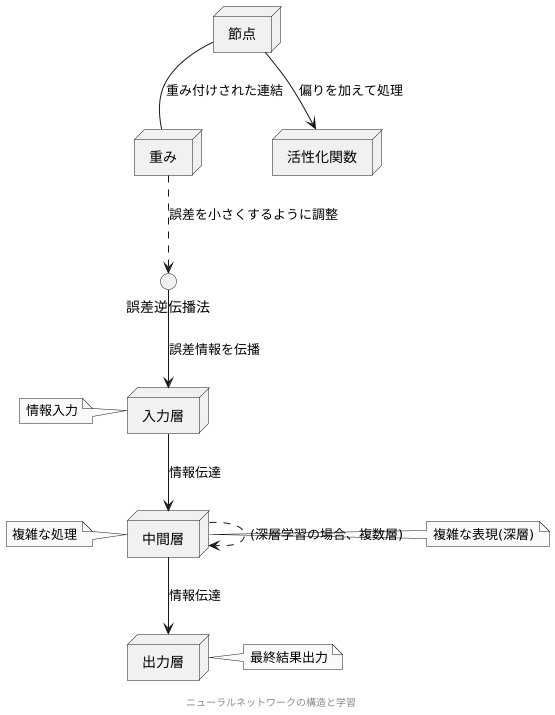
人工知能の根幹をなすニューラル網は、人間の脳の神経細胞の働きを模倣した数理模型です。この網は、情報を入力する層、中間で複雑な処理を行う層、そして最終結果を出力する層という、多層構造を持っています。各層は多数の計算単位である節点で構成され、節点同士は重み付けされた連結で繋がっています。入力層から入った情報は、中間層へと伝達され、各節点では入力値に重みをかけ、さらに偏りを加えて活性化関数という処理を通して出力値を決めます。この一連の流れが繰り返されることで、入力された情報から複雑な規則性や関連性を見つけ出すことができるのです。特に、中間層が複数あるものを深層学習と呼び、より深くすることで、複雑な表現が可能となり、高度な処理を実現できます。学習とは、与えられた情報に対する出力と正解との誤差を小さくするように、重みや偏りを調整する過程です。この調整には、誤差逆伝播法という方法が用いられ、出力層から入力層へと誤差情報を伝播させ、各層の重みを修正していきます。
学習データの重要性

深層学習の能力は、学習に使う情報の質と量に大きく左右されます。質の高い情報をたくさん用意することが、深層学習を成功させるための重要な点です。学習させる情報が少なかったり、偏っていたりすると、人工知能は応用がきかなくなり、知らない情報に対して正確な予測や判断ができません。例えば、猫の画像を認識する人工知能を作る場合、色々な種類の猫の画像や背景、明るさで撮った画像など、色々な情報を用意する必要があります。もし、特定の種類の猫の画像だけで学習させてしまうと、その種類以外の猫を認識することが難しくなります。また、学習させる情報に誤りがあると、人工知能の能力に悪い影響を与えます。誤りとは、間違った分類がされた情報や、余計な情報が含まれている情報のことです。これらの誤りを取り除くために、情報の整理を行うことが大切です。情報の整理には、情報の掃除や基準化、拡張など色々な方法があります。情報の掃除は、間違った情報や足りない部分を取り除く作業です。基準化は、情報の値を一定の範囲にすることで、学習の安定性を高める効果があります。情報の拡張は、今ある情報を加工して、学習させる情報の種類を増やす方法です。例えば、画像を回転させたり、拡大縮小したりすることで、新しい情報を作り出すことができます。質の高い学習情報を確保し、適切な整理を行うことで、深層学習の能力を最大限に引き出すことができます。
| 要因 | 内容 | 詳細 |
|---|---|---|
| 学習情報の質 | 重要性 | 深層学習の能力を大きく左右する |
| 質の低い場合 |
|
|
| 学習情報の整理 | 重要性 | 誤りを取り除く |
| 情報の掃除 | 誤った情報や足りない部分を取り除く | |
| 基準化 | 情報の値を一定の範囲にする(学習の安定性向上) | |
| 情報の拡張 | 既存の情報を加工して種類を増やす |
深層学習の応用事例

深層学習は多岐にわたる分野で活用され、社会に革新をもたらしています。画像認識の分野では、顔認証技術や物体検出、画像の自動分類などで目覚ましい成果を上げています。例えば、携帯端末の顔認証によるロック解除や、自動運転車両における障害物検知システムなどが実用化されています。音声認識の分野では、音声アシスタントや自動翻訳、音声からの文字変換などで、その精度が向上しています。音声で指示するだけで音楽再生や情報検索が可能な機器は、その代表例と言えるでしょう。自然言語処理の分野では、機械翻訳や文章の自動生成、質問応答システムなどが進化しています。異なる言語間の翻訳や、特定のテーマに基づいた文章作成などが、深層学習によって効率化されています。医療分野では、画像診断支援や新薬開発、遺伝子情報解析など、研究開発が加速しています。レントゲンや断層写真から病変を自動で見つけ出す技術や、新薬の候補となる物質を探索する試みなどが進められています。金融分野では、不正行為の検知やリスク管理、信用評価などに利用されています。クレジットカードの不正利用を早期に発見したり、融資の際の返済能力を予測することなどが可能になっています。これらの事例は深層学習の潜在能力を示すほんの一例であり、今後の発展により、私たちの生活や社会はさらに豊かになると考えられます。
| 分野 | 応用例 | 深層学習による貢献 |
|---|---|---|
| 画像認識 | 顔認証、物体検出、画像分類 | 自動運転の障害物検知、顔認証ロック解除 |
| 音声認識 | 音声アシスタント、自動翻訳、音声文字変換 | 音声指示による音楽再生、情報検索 |
| 自然言語処理 | 機械翻訳、文章自動生成、質問応答 | 翻訳の効率化、テーマに基づいた文章作成 |
| 医療 | 画像診断支援、新薬開発、遺伝子情報解析 | 病変の自動検出、新薬候補物質の探索 |
| 金融 | 不正検知、リスク管理、信用評価 | 不正利用の早期発見、返済能力予測 |
深層学習の今後の展望

深層学習は目覚ましい進歩を遂げ、今後も様々な領域で変革をもたらすと期待されています。研究開発は、高性能な模型の構築、学習効率の向上、判断根拠の明確化など、多岐にわたる方向へ進んでいます。高性能な模型の構築では、新たな神経回路網の構造や学習手法の研究が活発です。例えば、ある構造は自然言語処理で大きな成果を上げており、他の領域への応用も期待されています。学習効率の向上では、少ない資料でも学習できる手法や、異なる種類の資料を組み合わせて学習する手法が研究されています。これにより、資料が限られた領域でも深層学習の活用が見込めます。判断根拠の明確化では、深層学習模型の判断理由を説明する技術の開発が進められています。これにより、意思決定の過程を理解し、より信頼性の高い仕組みを構築できます。また、深層学習は倫理的な問題とも深く関わっています。差別的な判断をしないための対策や、個人情報を保護しながら活用するための技術が研究されています。深層学習は社会を大きく変える可能性を秘める一方、倫理的な課題も抱えています。技術の発展と共に、倫理的な側面にも配慮し、適切に活用していくことが重要です。
| 研究開発の方向性 | 内容 | 期待される効果 |
|---|---|---|
| 高性能な模型の構築 | 新たな神経回路網の構造や学習手法の研究 | 自然言語処理以外の領域への応用 |
| 学習効率の向上 | 少ないデータでの学習、異なる種類のデータを組み合わせた学習 | データが限られた領域での深層学習の活用 |
| 判断根拠の明確化 | 深層学習モデルの判断理由を説明する技術の開発 | 意思決定過程の理解、信頼性の高いシステムの構築 |
| 倫理的な問題への対応 | 差別的な判断をしないための対策、個人情報保護技術の研究 | 倫理的な懸念の軽減、適切な深層学習の活用 |