
効率的な探索を実現する:αβ法の徹底解説

DXを学びたい
先生、デジタル変革で使われる『αβ法』という言葉について教えてください。探索アルゴリズムの一種で、不要な探索を減らすと聞きました。具体的にどんなものなのでしょうか?

DXアドバイザー
はい、αβ法は、ある問題に対する最適な解を見つけ出すための探索方法の一つです。特に、相手がいるゲームのような状況で、自分が有利になるように戦略を立てる際に役立ちます。無駄な選択肢を早い段階で省くことで、効率的に最適な解を探せるんですよ。
DXを学びたい
相手がいるゲーム、ですか。ということは、囲碁や将棋のようなものでしょうか? 不要な選択肢を省く、というのは、具体的にどういうことですか?
DXアドバイザー
その通り、囲碁や将棋のようなゲームでよく使われます。例えば、ある局面で、どう頑張っても相手が絶対に勝つような手があるとわかったら、それ以上その手を深く考える必要はありませんよね? αβ法は、そういった「これ以上調べても無駄だ」という状況を判断し、探索を打ち切ることで、計算量を減らすのです。
αβ法とは。
「デジタル変革」に関連する用語で、『アルファベータ法』という探索手法があります。これは、ミニマックス法と同様の考え方に基づいており、無駄な探索を省くことで効率を高めます。
探索アルゴリズムにおける効率性の重要性

探索手順は、人工知能や遊戯開発など、多岐にわたる領域で中心的な役割を担っています。特に、入り組んだ問題や膨大な量の情報を扱う際には、能率的な探索が不可欠です。もし探索が非能率的であれば、計算資源を浪費し、現実的な時間内での問題解決が難しくなる可能性があります。したがって、探索手順の性能を向上させることは、実用的な応用において非常に重要な課題です。能率的な探索手順を選択し、適切に実装することで、計算時間を短縮し、より複雑な問題を解決できるようになります。探索範囲を網羅的に調べるのではなく、有望な領域に焦点を絞り、不要な探索を削減することが、能率的な探索を実現するための鍵となります。また、手順の選択だけでなく、情報の構造や問題の特性を考慮し、最適な探索戦略を立てることも重要です。例えば、問題が特定の性質を持っている場合、その性質を利用した特殊な手順を用いることで、大幅な性能向上が期待できます。さらに、並行処理などの技術を活用することで、探索処理を高速化することも可能です。能率的な探索手順の開発と応用は、人工知能技術の発展に大きく貢献すると考えられます。
ミニマックス法とその限界

ミニマックス法は、双方が完全に情報を把握している状況下で、自身の利益を最大化し、相手の損失を最大化するという考えに基づいた意思決定手法です。取り得る全ての行動を評価し、相手が最善を尽くした場合でも、自身の利益が最大となる選択肢を選びます。しかし、この手法には計算量の問題があります。局面数や選択肢が増えると、計算量は指数関数的に増大し、現実的な時間内での探索が困難になります。これは、ミニマックス法がゲームの全ての可能性を探索しようとするため、不要な探索も含まれてしまうためです。例えば、ある局面で既に自身にとって非常に不利な状況が判明した場合、それ以上の探索は意味を成しません。このような問題を解決するために、探索範囲を絞り込むさまざまな手法が考案されています。その一つが、不要な探索を事前に排除するαβ法です。ミニマックス法の限界を理解し、より効率的な探索手法を用いることで、複雑な状況下でもより良い決断を下せるようになります。
| 項目 | 説明 |
|---|---|
| ミニマックス法の基本 | 双方が完全な情報を持ち、自身の利益最大化と相手の損失最大化を目指す意思決定手法 |
| ミニマックス法の問題点 | 計算量の問題(局面数・選択肢増加で指数関数的に増大)、不要な探索 |
| 解決策の例 | αβ法(不要な探索を事前に排除) |
| 結論 | ミニマックス法の限界を理解し、効率的な探索手法を用いることが重要 |
αβ法の基本的な仕組み

αβ法は、ある戦略において最善手を効率的に見つけ出すための探索手法です。これは、ミニマックス法という別の探索手法を改良したもので、同じ結果をより少ない計算量で得られるように工夫されています。その核心は、探索の過程で無駄な部分を省く「枝刈り」という技術にあります。具体的には、α値とβ値という二つの基準値を設け、この基準に基づいて探索範囲を狭めていきます。α値は、探索中の局面において、自分がこれまでに発見した最良の選択肢の価値を示します。したがって、α値以上の価値が見込める選択肢が見つかれば、それ以下の選択肢を調べる必要はありません。一方、β値は、相手にとって最良の選択肢の価値を表します。相手がβ値以上の選択肢を選ぶ場合、自分はその局面を選ぶ意味がなくなります。αβ法では、探索中にα値がβ値を超えた場合、それ以降の探索を打ち切ります。この処理を枝刈りと呼び、探索範囲を大幅に削減し、計算量を減らすことができます。この手法を用いることで、より深い探索が可能となり、複雑な問題にも対応できます。ただし、その効率は探索する順番に大きく左右されます。最良と思われる選択肢から順に検討することで、より多くの枝刈りが可能になります。αβ法は、遊戯盤面における最適解の探索に限らず、様々な分野の問題解決に応用できる強力な手法です。
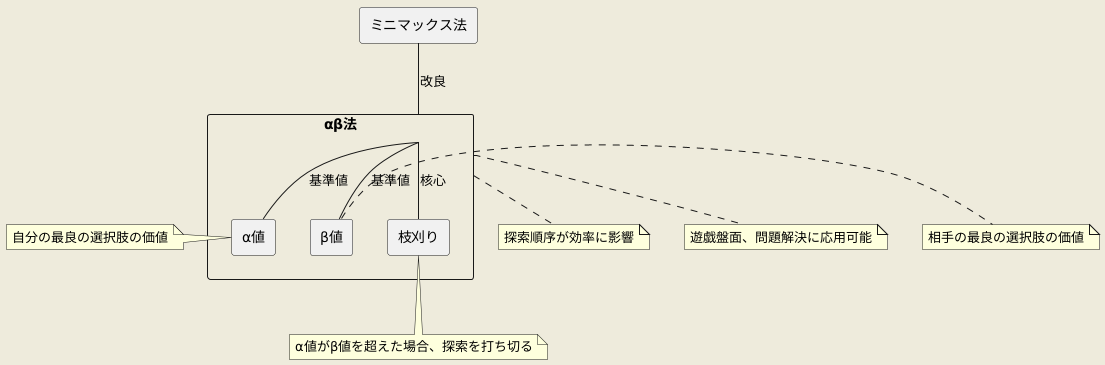
α値とβ値の役割

α値とβ値は、探索範囲を狭める上で重要な役割を担います。これらは、探索中に変動し、より効率的な探索を可能にします。α値は、自身にとって現時点で確保できる最低限の評価値を示します。探索中にこれより低い評価値が見つかれば、その選択肢は考慮されません。なぜなら、既にそれ以上の評価値が保証されているからです。一方、β値は、相手にとって現時点で確保できる最大限の評価値を示します。探索中にこれより高い評価値が見つかれば、その選択肢は同様に無視されます。相手は既にそれ以下の評価値を保証できるからです。α値とβ値は相互に影響し合い、α値がβ値以上になった場合、それ以降の探索は打ち切られます。これは、相手が自身にβ値以下の評価を強いることができるため、それ以上探索する意味がないからです。初期値として、α値は負の無限大、β値は正の無限大に設定され、探索の進行とともにこれらの値は更新され、探索範囲が絞り込まれていきます。
| 値 | 意味 | 初期値 | 更新 | 探索打ち切り条件 |
|---|---|---|---|---|
| α値 | 自身にとって現時点で確保できる最低限の評価値 | 負の無限大 | より高い評価値が見つかると更新 | α値 >= β値 |
| β値 | 相手にとって現時点で確保できる最大限の評価値 | 正の無限大 | より低い評価値が見つかると更新 | α値 >= β値 |
αβ法の利点と注意点

αβ法は、盤面評価に基づき、最善手を探索する手法です。利点として、無駄な探索を減らせる点が挙げられます。これは、探索範囲を絞り込むことで、計算量を抑え、より深い読みを可能にするため、質の高い戦略立案に繋がります。特に、時間的な制約がある状況下では、その効果を発揮します。注意点としては、探索する順番が結果に影響を与えることです。効率的な枝刈りのためには、有望な手から優先的に検討する工夫が求められます。また、ゲームによっては、必ずしも最適解にたどり着けるとは限りません。複雑なゲームでは、探索深度に限界があるため、他の手法との組み合わせも視野に入れるべきでしょう。さらに、実装が複雑になる傾向があります。α値とβ値の管理を誤ると、誤った枝刈りが発生する可能性があるため、実装後の検証は徹底的に行う必要があります。これらの点に留意すれば、αβ法は強力な問題解決の道具となり得ます。
| 項目 | 内容 |
|---|---|
| 概要 | 盤面評価に基づき最善手を探索する手法 |
| 利点 |
|
| 注意点 |
|
| その他 | 複雑なゲームでは探索深度に限界があるため、他の手法との組み合わせを検討 |
αβ法の応用例

排他的二者間遊戯において、完全に情報が公開され、かつ有限な状態数を持つ場合、先読みによる思考判断手法であるアルファベータ法が有効です。具体例として、盤上遊戯が挙げられます。互いの利を追い求める中で、相手の出方を予想しつつ最善手を模索します。この手法により、計算機が人間に匹敵する水準で遊戯を行うことが現実となりました。また、日程計画問題や最適化問題といった、遊戯以外の分野にも応用可能です。日程計画問題では、複数作業を滞りなく行うための最良計画を策定します。最適化問題では、制約下で目的関数を最大化または最小化する解を求めます。人工知能の分野では、計画立案問題や推論問題に応用されています。計画立案問題では、目標達成のための最適行動を生成し、推論問題では、既存知識から新たな知識を導き出します。これらの問題を効率的に解決することで、より高度な人工知能を開発できます。今後も多様な分野での応用が期待されています。
| 項目 | 説明 | 具体例/応用例 |
|---|---|---|
| アルファベータ法 | 排他的二者間遊戯において、完全に情報が公開され、かつ有限な状態数を持つ場合に有効な先読みによる思考判断手法 | 盤上遊戯、日程計画問題、最適化問題、計画立案問題、推論問題 |
| 盤上遊戯 | 互いの利を追い求める中で、相手の出方を予想しつつ最善手を模索 | – |
| 日程計画問題 | 複数作業を滞りなく行うための最良計画を策定 | – |
| 最適化問題 | 制約下で目的関数を最大化または最小化する解を求める | – |
| 人工知能への応用 | 計画立案問題:目標達成のための最適行動を生成、推論問題:既存知識から新たな知識を導き出す | より高度な人工知能の開発 |
| 今後の展望 | 多様な分野での応用が期待される | – |